聚焦於 How does it work,本篇要來探討 BeyondCorp 架構中 Access Control 具體的數據流。我們將從 Device Inventory Service 記錄了哪種數據開始,到數據整合、觸發 Trust Inference 判斷用戶/設備的信任等級,到作爲 Access Control Engine 的輸入。
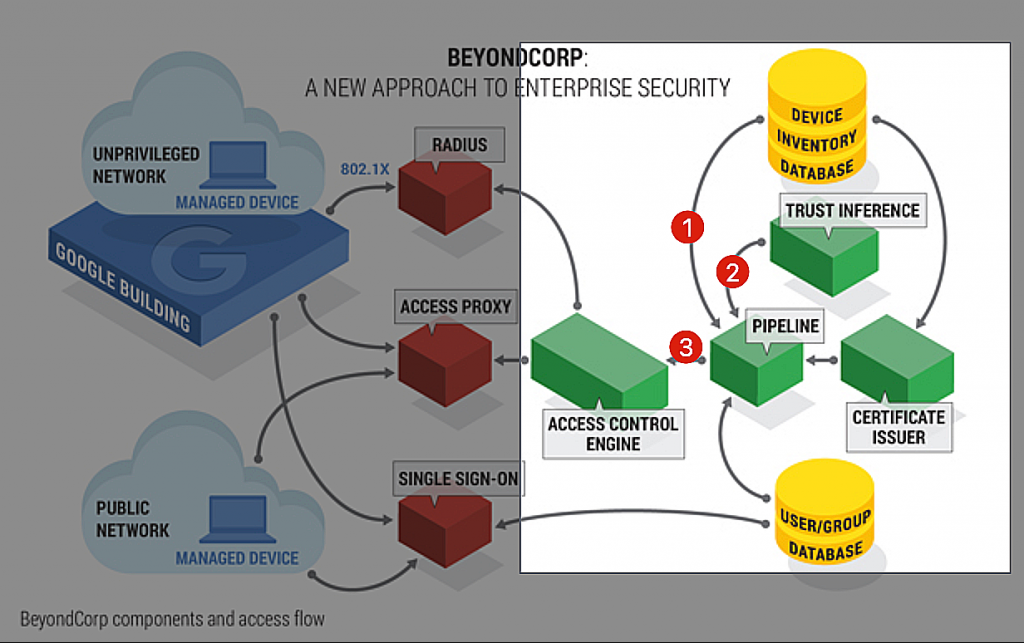
圖 1. Access Control flow 01 (source: https://www.beyondcorp.com/)
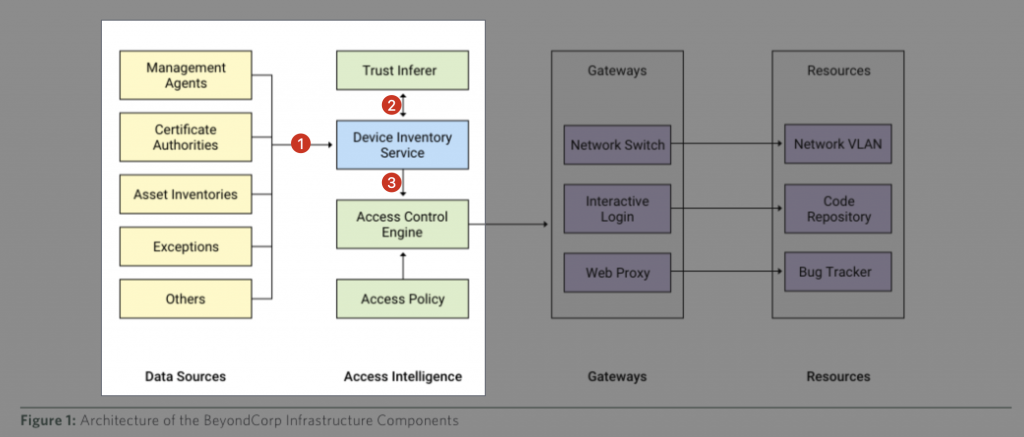
圖 2. Access Control flow 02 (source: How Google did it: "Design to Deployment at Google")
本篇內容大多爲論文翻譯,詳見出處:How Google did it: "Design to Deployment at Google"
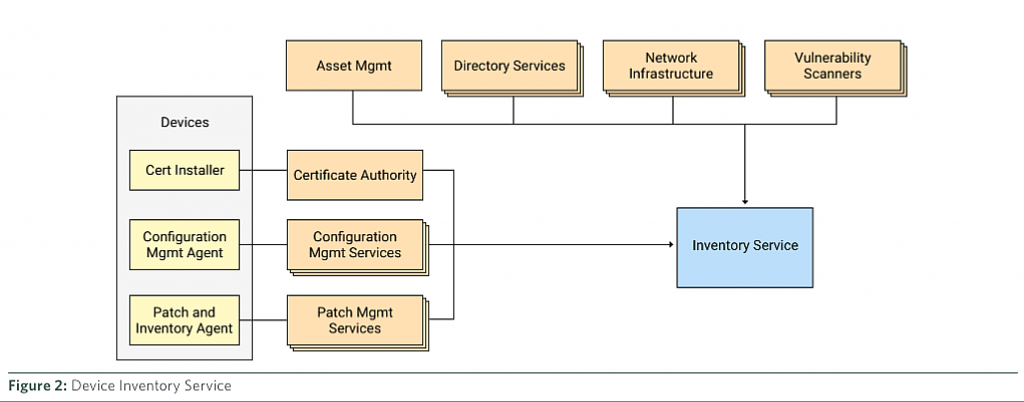
圖 3. Device Inventory Service (source: How Google did it: "Design to Deployment at Google")
前篇有提到,Device Inventory Service 是一個負責持續收集、處理並發佈已知設備狀態變更的系統。它會做的事情是負責從各種各樣的來源系統(比如 Active Directory、Configuration Management Systems、Corporate Asset Management 、網絡基礎設施如 ARP tables 等)收集信息,所收集的信息包括設備固有的信息(網卡、設備號等)以及設備上的運行信息(操作系統版本、補丁更新情況等)。
自從部署 Device Inventory Service 的初始階段以來,Google 已經導入了來自 15 個數據源的數十億個增量,平均每天約 300 萬個,總計超過 80TB。(數據出自 2016 年的論文,現在肯定不止這樣)保留歷史數據對我們理解特定設備的端到端生命周期、跟蹤和分析整個設備群趨勢,以及進行安全審計和法證調查至關重要。
Device Inventory Service 收集到的數據可以分成兩類,一類是由程序生成的 observed data,一類是由管理人員手動維護的 prescribed data。
由程序生成的 Observed data,例如:
由管理人員手動維護的 Prescribed data,例如:
Observed Data 每天都在大量生成,而 Prescribed Data 相對而言是靜態,鮮少變化的。
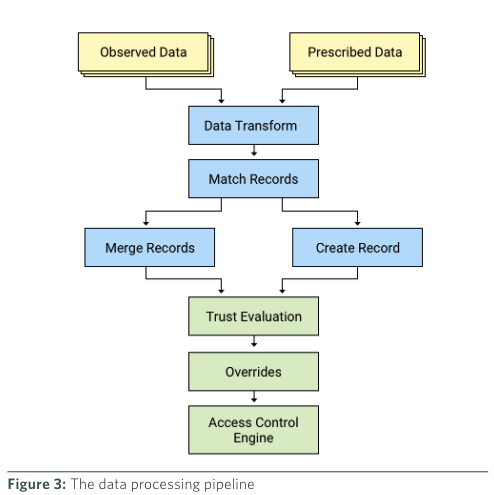
圖 4. Data Processing Pipeline (source: How Google did it: "Design to Deployment at Google")
为了保持 Device Inventory Service 的即時性,需要經歷幾個處理階段。
首先,所有數據必須轉換成統一的數據格式(對應到圖 4. 的 Data Transform)。某些數據來源,例如內部或開源解決方案,可以設定成在提交更改時即時將其發佈到 Device Inventory Service。然而,其他來源,尤其是第三方數據源,無法擴展以實現即時發佈變更,因此需要定期 polling 以獲取更新。
當數據格式統一後,所有的數據必須進行相關性分析(對應到圖 4. 的 Match Records)。這一階段的主要目的是要得到以設備爲主鍵的唯一的數據記錄,也即一個設備只會有一筆記錄。
爲什麼一個設備可能會在 Device Inventory Service 中存在多筆記錄呢?會有這個情況發生是因爲不同數據源(比如 Active Directory、Configuration Management Systems、Corporate Asset Management 、網絡基礎設施如 ARP tables 等)對同一個設備的描述信息可能不盡相同。
當我們確定兩筆記錄其實是在描述同個設備時,這兩筆記錄會被合併爲一筆。聽起來很簡單,要實踐卻很複雜。因爲許多數據源之間沒有共享相互重疊的 identifier。
舉例來說,以下不同數據源都存放針對同個設備的信息,但每列都是一筆記錄:
直到 Inventory reporting agent 回報這幾筆記錄實際上是在描述同個設備,這些記錄才會被合併爲一筆唯一的記錄(對應到圖 4. 的 Merge Records 和 Create Record)。
一旦設備信息在 Device Inventory Service 中被合併成一筆唯一的記錄,Trust Inference 就會被觸發以進行信任等級的分配(對應到圖 4. 的 Trust Evaluation),信任等級結果會被存放到 Device Inventory Service。分配信任等級的過程會參考 Device Inventory Service 中的許多欄位。例如,設備需要符合以下條件才能被分配到高信任等級(可以聯想爲 “我的辦公設備需要以下條件才能被分配到高信任等級,所以才能幹特定的事情”):
這個信任等級判斷的步驟在第一關先篩選了一遍流量,從而減少了需要推送到 Gateways 的訪問數量,也減少了在訪問請求時需要消耗的算力。這一步還使我們可以確保所有的 Gateway 都使用一致的數據集。此外,我們還可以在此階段對不活躍的設備進行信任變更。例如,在過去,對於可能受到 Stagefright 影響的設備,我們在這些設備申請訪問前就拒絕了其訪問權限。
Stagefright (bug) 是 2015 年發現的 Android 系統中的安全漏洞,攻擊者可以透過遠程執行和特權提升,在受害者設備上任意操作。
當然,判斷設備的信任等級這種預計算方法是有缺點的,並不能完全依賴它。例如,Access Policy 可能需要額外的實時 MFA。
不過令人驚訝的是,policy 或設備狀態變更,以及 Gateways 實施這些變更,這中間的延遲並未被證明是一個問題。更新延遲 (update latency) 通常少於一秒。比起延遲問題,並非所有信息都可以預先計算是更顯著的問題。
Trust Inference 對於特定設備應該應用哪個信任層級擁有最終決定權。信任等級判斷的過程考慮了 Device Inventory Services 中的預設例外情況,這些例外情況允許覆蓋一般 access policy。(對應到圖 4. 的 Overrides)
例外情況主要是一種機制,旨在減少 policy 的變動造成的部署延遲。例如,物聯網設備可能會受到例外情況的處理,並被歸納到它們自己的信任層級中,因為在這些設備上安裝和維護證書可能是不切實際的。
在這些情況下,最迅速的行動可能是在安全掃描程序更新以查找該設備之前,立即封鎖易受零日漏洞攻擊的特定設備,或允許不受信任的設備連接到實驗室網絡。
至此我們終於把所有架構元件講完啦!!(流下感動的淚水)在分散式系統架構中,單獨把所有組件拎出來討論,最後再看整體架構(包含連線),筆者認爲是必要的學習過程。前提是首先有個整體的架構圖,知道自己在解決什麼問題。
話說看完整個架構居然才十天,好完整的數字🥰
明天我們來看整體架構(包含連線),來學習第一篇論文 An overview: "A New Approach to Enterprise Security" 中提出的 end-to-end example, 把整個架構流程過一遍作爲架構元件的小結。這樣我們就能夠順利地進行到下一個討論階段 —— Google 是如何將內部轉型到 BeyondCorp 架構的?轉型過程中遇到了哪些挑戰和 Lessons learned?
明天見!

